拆包包游戏源码2022(源码解读)
▌写在前面:
大家好,我是大吴号,在前面的文章中,尼恩已经再一次的进行了通讯协议的重新选择
这就是:放弃了大家非常熟悉的json 格式,选择了性能更佳的 protobuf协议
在上一篇文章中,并且完成了netty 和 protobuf协议整合实战
具体的文章为: netty+protobuf 整合一:实战案例,带源码
另外,专门开出一篇文章,介绍了通讯消息数据包的几条设计准则
具体的文章为: netty +protobuf 整合二:protobuf 消息通讯协议设计的几个准则
在开始聊天器实战开发之前,还有一个非常基础的问题,需要解决:
这就是通讯的粘包和半包问题
注:本文以 pdf 持续更新,最新尼恩 架构笔记、面试题 的pdf文件,请到《技术自由圈》公众号获取
▌什么是粘包和半包?
先从数据包的发送和接收开始讲起
发送一次数据,举例如下:
channel.writeandflush(buffer);读取一次数据,举例如下:
public void channelread(channelhandlercontext ctx, object msg){ bytebuf bytebuf = (bytebuf) msg; //....}我们的理想是:发送端每发送一个buffer,接收端就能接收到一个一模一样的buffer
然而,理想很丰满,现实很骨感
在实际的通讯过程中,并没有大家预料的那么完美
一种意料之外的情况,如期而至这就是粘包和半包
那么,什么是粘包和半包?
粘包和半包定义如下:
▌粘包和半包 图解:
上面的理论比较抽象,下面用一幅图来形象说明
下图中,发送端发出4个数据包,接受端也接受到了4个数据包但是,通讯过程中,接收端出现了 粘包和半包
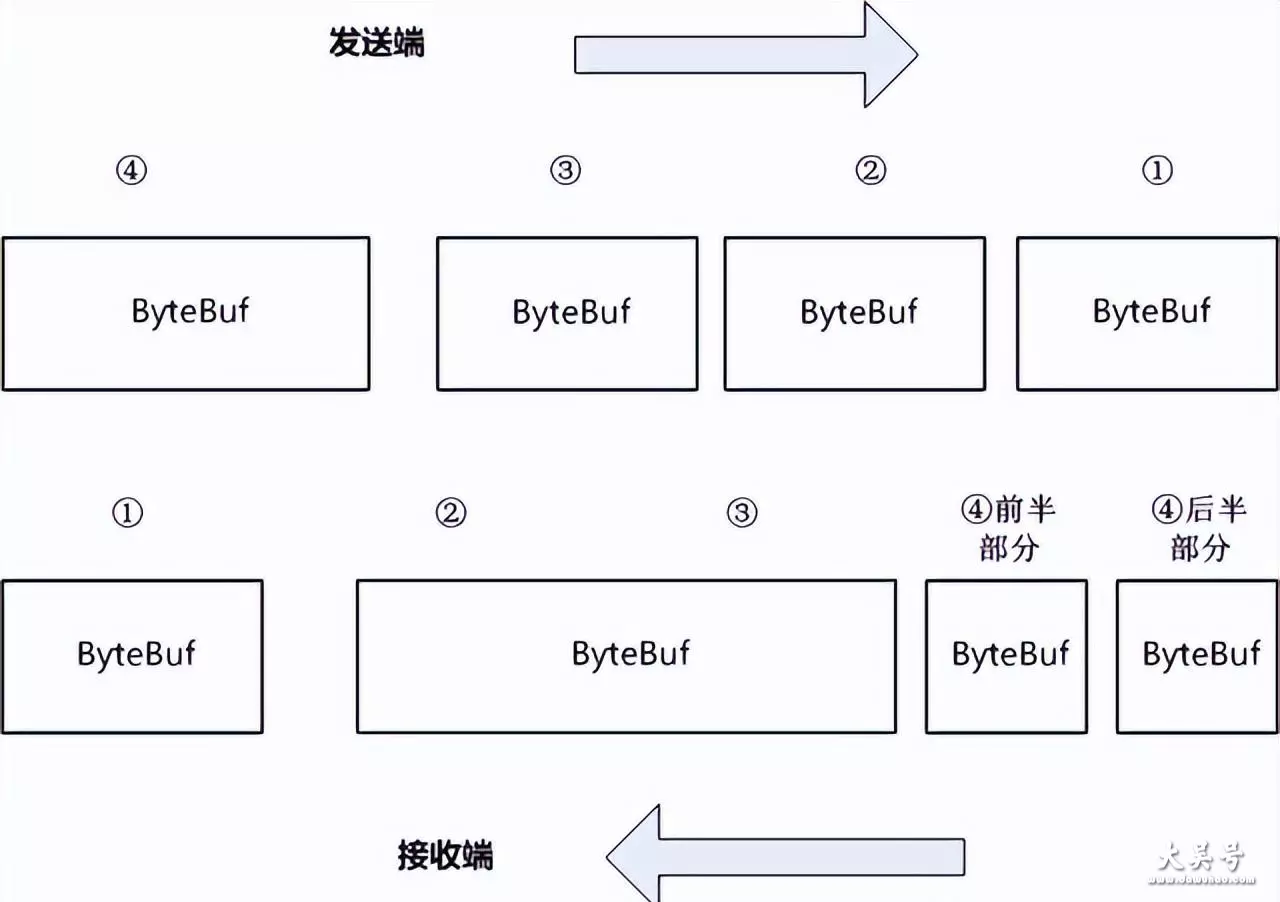
接收端收到的第一个包,正常
接收端收到的第二个包,就是一个粘包 将发送端的第二个包、第三个包,粘在一起了
接收端收到的第三个包,第四个包,就是半包将发送端的的第四个包,分开成了两个了
▌半包的实验:
由于在前文 netty+protobuf 整合一:实战案例,带源码 的源码中,没有看到异常的现象是因为代码屏蔽了半包的输出,所以看到的都是正常的数据包
稍微调整一下,在前文解码器的代码,加上半包的提示信息输出,就可以看到半包的提示
示意图如下:
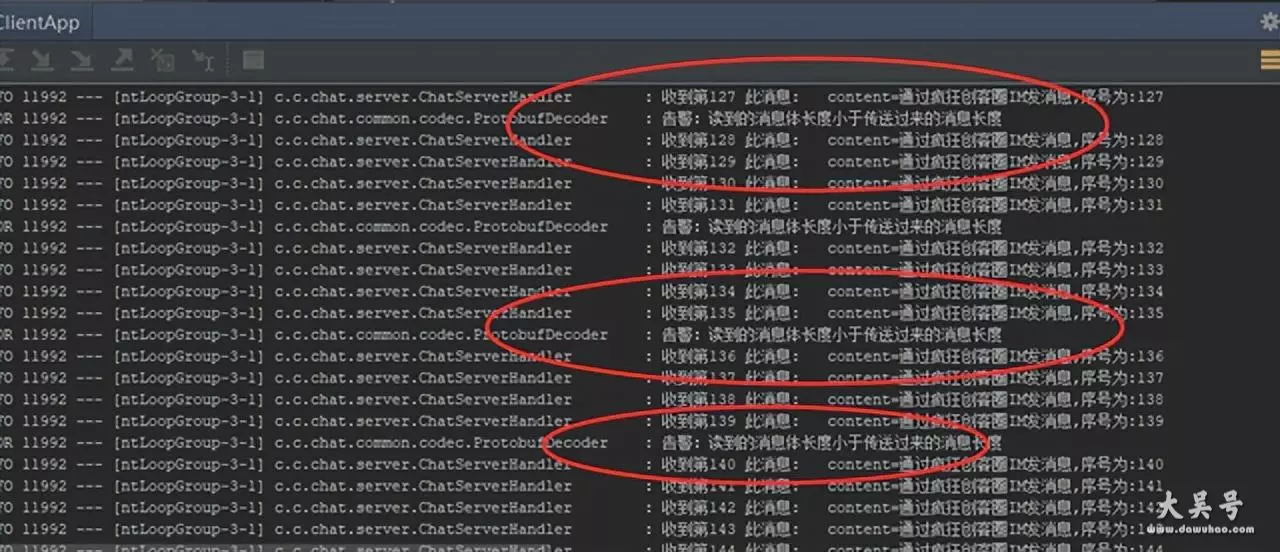
调整过的半包警告的代码,如下:
/** * 解码器 * */public class protobufdecoder extends bytetomessagedecoder { //.... protected void decode(channelhandlercontext ctx, bytebuf in, listobject out) throws exception { //... // 读取传送过来的消息的长度 int length = in.readunsignedshort(); //... if (length in.readablebytes()) { // 读到的半包 // ... log.error("告警:读到的消息体长度小于传送过来的消息长度"); return; } //... 省略了正常包的处理 }}具体的源码,请参见本文末的源码工程:netty 粘包/半包原理与拆包实战 源码
可以根据文末源码,进行实验
▌粘包和半包更全实验:
上面的实例,只能看到半包的结果,看不到粘包的结果
为了看到粘包的场景,这里,不使用protobuf 协议,直接使用缓冲区进行读写通讯,设计了一个的简单的演示实验案例
案例已经设计好,可以根据文末源码,进行实验
运行实例,不仅可以看到半包的提示信息输出,而且可以看到粘包的提示信息输出,示意图如下:
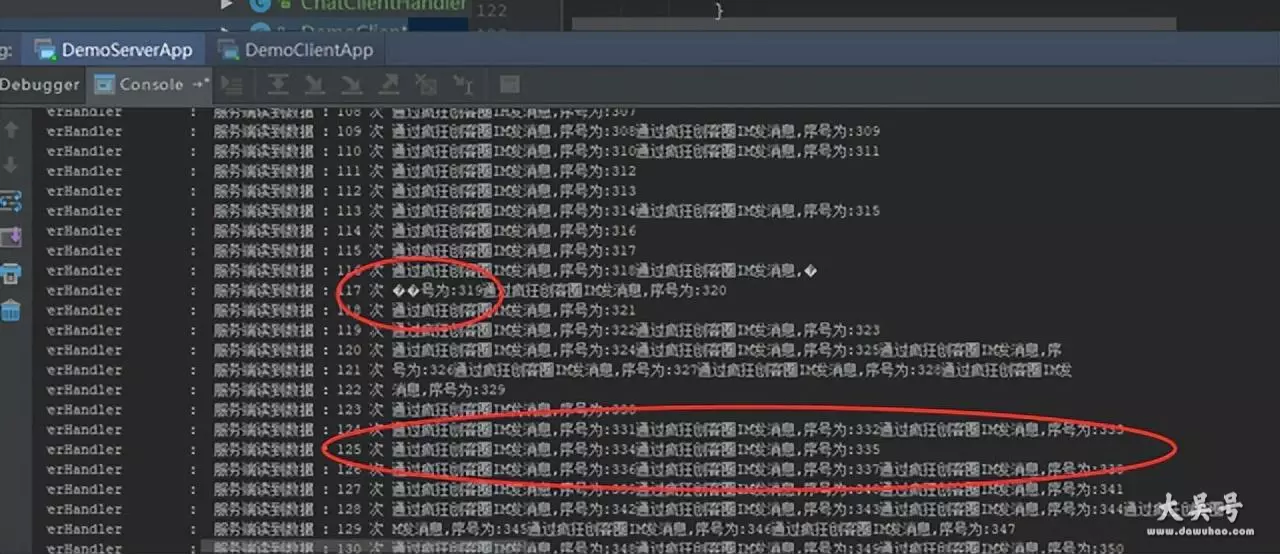
我们可以看到,服务器收到的数据包,有包含多个发送端数据包的,这就是粘包了
另外,接收端还有出现乱码的数据包,就是只包含部分发送端数据,这就是半包了
这个实例的源码,直接简化了前面的基于protobuf协议通讯的实例源码代码的逻辑结构,是一样的
本实验的具体的源码,还是请参见本文末的源码工程:netty 粘包/半包原理与拆包实战 源码
▌粘包和半包原理:
这得从底层说起
在操作系统层面来说,我们使用了 tcp 协议
这就是粘包和半包的根源
首先,上层应用层每次读取底层缓冲的数据容量是有限制的,当tcp底层缓冲数据包比较大时,将被分成多次读取,造成断包,在应用层来说,就是半包
其次,如果上层应用层一次读到多个底层缓冲数据包,就是粘包
如何解决呢?
基本思路是,在接收端,需要根据自定义协议来,来读取底层的数据包,重新组装我们应用层的数据包,这个过程通常在接收端称为拆包
▌拆包的原理:
拆包基本原理,简单来说:
- 接收端应用层不断从底层的tcp 缓冲区中读取数据
- 每次读取完,判断一下是否为一个完整的应用层数据包如果是,上层应用层数据包读取完成
- 如果不是,那就保留该数据在应用层缓冲区,然后继续从 tcp 缓冲区中读取,直到得到一个完整的应用层数据包为止
- 至此,半包问题得以解决
- 如果从tcp底层读到了多个应用层数据包,则将整个应用层缓冲区,拆成一个一个的独立的应用层数据包,返回给调用程序
- 至此,粘包问题得以解决
▌netty 中的拆包器:
拆包这个工作,netty 已经为大家备好了很多不同的拆包器本着不重复发明轮子的原则,我们直接使用netty现成的拆包器
netty 中的拆包器大致如下:
- 固定长度的拆包器 fixedlengthframedecoder
每个应用层数据包的都拆分成都是固定长度的大小,比如 1024字节
这个显然不大适应在 java 聊天程序 进行实际应用
- 行拆包器 linebasedframedecoder
每个应用层数据包,都以换行符作为分隔符,进行分割拆分
这个显然不大适应在 java 聊天程序 进行实际应用
- 分隔符拆包器 delimiterbasedframedecoder
每个应用层数据包,都通过自定义的分隔符,进行分割拆分
这个版本,是linebasedframedecoder 的通用版本,本质上是一样的
这个显然不大适应在 java 聊天程序 进行实际应用
- 基于数据包长度的拆包器 lengthfieldbasedframedecoder
将应用层数据包的长度,作为接收端应用层数据包的拆分依据按照应用层数据包的大小,拆包这个拆包器,有一个要求,就是应用层协议中包含数据包的长度
这个显然比较适和在 java 聊天程序 进行实际应用下面我们来应用这个拆分器
▌拆包之前的消息包装:
在使用
lengthfieldbasedframedecoder 拆包器之前 ,在发送端需要对protobuf 的消息包进行一轮包装
发送端包装的方法是:
在实际的protobuf 二进制消息包的前面,加上四个字节
前两个字节为版本号,后两个字节为实际发送的 protobuf 的消息长度

强调一下,二进制消息包装,在发送端进行
修改发送端的编码器 protobufencoder ,代码如下:
/** * 编码器 */ public class protobufencoder extends messagetobyteencoderprotomsg.message {@overrideprotected void encode(channelhandlercontext ctx, protomsg.message msg, bytebuf out) throws exception{ byte bytes = msg.tobytearray();// 将对象转换为byte int length = bytes.length;// 读取 protomsg 消息的长度 bytebuf buf = unpooled.buffer(2 + length); // 先将消息协议的版本写入,也就是消息头 buf.writeshort(constants.protocol_version); // 再将 protomsg 消息的长度写入 buf.writeshort(length); // 写入 protomsg 消息的消息体 buf.writebytes(bytes); //发送 out.writebytes(buf); }}发送端的步骤是:
- 先将消息协议的版本写入,也就是消息头
buf.writeshort(constants.protocol_version);
- 再将 protomsg 消息的长度写入 buf.writeshort(length);
▌开发一个接收端的自定义拆包器:
使用netty中,基于长度域拆包器
lengthfieldbasedframedecoder,按照实际的应用层数据包长度来拆分
需要做两个工作:
- 设置长度信息(长度域)在数据包中的位置
- 设置长度信息(长度域)自身的长度,也就是占用的字节数
在前面的小节中,我们的长度信息(长度域)的占用字节数为 2个字节; 在报文中的所处的位置,长度信息(长度域)处于版本号之后
版本号是2个字节,从0开始数,长度信息(长度域)的在数据包中的位置为2
这些数据定义在constansts常量类中
public class constants{//协议版本号public static final short protocol_version = 1;//头部的长度: 版本号 + 报文长度public static final short protocol_headlength = 4;//长度的偏移public static final short length_offset = 2;//长度的字节数public static final short length_bytes_count = 2;}有了这些数据之后,可以基于netty 的长度拆包器
lengthfieldbasedframedecoder, 开发自己的长度分割器
新开发的分割器为packagespliter,代码如下:
package com.crazymakercircle.chat.common.codec;public class packagespliter extends lengthfieldbasedframedecoder{ public packagespliter() { super(integer.max_value, constants.length_offset,constants.length_bytes_count); } @override protected object decode(channelhandlercontext ctx, bytebuf in) throws exception { return super.decode(ctx, in); }}分割器 packagespliter 继承了
lengthfieldbasedframedecoder,传入了三个参数
- 长度的偏移量 ,这里是 constants.length_offset,值为 2
- 最大的应用包长度,这里是 integer.max_value,表示不限制
分割器 写好之后,只需要在 pipeline 的最前面加上这个分割器,就可以使用这个分割器(自定义的拆包器)
▌自定义拆包器的实际应用:
在服务器端的 pipeline 的最前面加上这个分割器,代码如下:
package com.crazymakercircle.chat.server;//...@service("chatserver")public class chatserver{ static final logger logger = loggerfactory.getlogger(chatserver.class);//...//有连接到达时会创建一个channelprotected void initchannel(socketchannel ch) throws exception{ //应用自定义拆包器 ch.pipeline().addlast(new packagespliter()); ch.pipeline().addlast(new protobufdecoder()); ch.pipeline().addlast(new protobufencoder()); // pipeline管理channel中的handler // 在channel队列中添加一个handler来处理业务 ch.pipeline().addlast("serverhandler", serverhandler);}});//....}在发送端的 pipeline 的最前面加上这个分割器,代码也是类似的, 这里不再赘述大家可以在文末源码查看
▌为什么拆包器要加在pipeline 的最前面?
这一点,需要从packagespliter 的根源讲起
下面是自定义分割器 packagespliter 的继承关系图
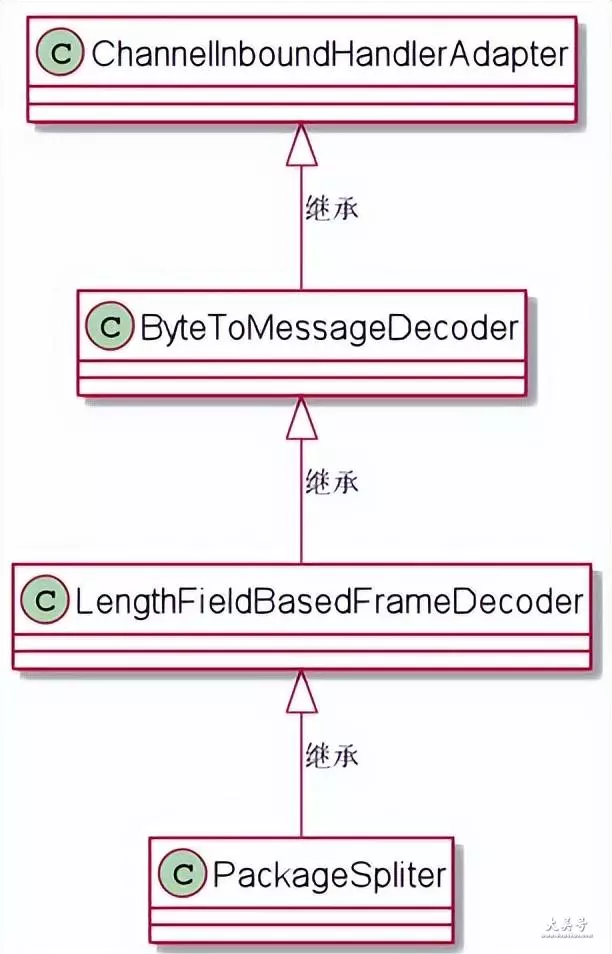
由此可见,分割器 packagespliter 继承了
channelinboundhandleradapter
本质上,它是一个入站处理器
在 关于netty的入站处理流程一文 pipeline inbound 中, 我们已经知道,netty的入站处理的顺序,是从pipelin 流水线的前面到后面
由于在入站过程中,解码器 protobufdecoder 进行应用层 protobuf 的数据包的解码,而在此之前,必须完成应用包的正确分割
所以, 分割器 packagespliter 必须处于入站流水线处理的第一站,放在最前面
题外话, packagespliter 分割器 和 protobufencoder 编码器 是否有关系呢?
从流水线处理的角度来说,是没有次序关系的
packagespliter 是入站处理器 在入站流程中用到
protobufencoder 是出站处理器,在出站流程中用到
特别提示一下: 发送端不存在粘包和半包问题这是接收端的事情
总之,在出站和入站处理流程上,分割器 packagespliter 和 编码器protobufencoder , 没有半毛钱关系的
▌写在最后:
至此为止,终于完成了 java 聊天程序实战的一些基础开发工作
包括了协议的编码解码包括了粘包和半包的拆包处理
大家好,我是大吴号,基本上可以开始 聊天器的正式设计和开发的详细讲解了
本文的源码工程:netty 粘包/半包原理与拆包实战 源码(
- 本实例是《netty 粘包/半包原理与拆包实战》 一文的源代码工程
▌技术自由的实现路径 pdf获取:
▌实现你的架构自由:
- 《吃透8图1模板,人人可以做架构》pdf
- 《10wqps评论中台,如何架构?b站是这么做的!》pdf
- 《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》pdf
- 《峰值21wqps、亿级dau,小游戏《羊了个羊》是怎么架构的?》pdf
- 《100亿级订单怎么调度,来一个大厂的极品方案》pdf
- 《2个大厂 100亿级 超大流量 红包 架构方案》pdf
… 更多架构文章,正在添加中
▌实现你的 响应式 自由:
- 《响应式圣经:10w字,实现spring响应式编程自由》pdf
- 这是老版本 《flux、mono、reactor 实战(史上最全)》pdf
▌实现你的 spring cloud 自由:
- 《spring cloud alibaba 学习圣经》 pdf
- 《分库分表 sharding-jdbc 底层原理、核心实战(史上最全)》pdf
- 《一文搞定:springboot、slf4j、log4j、logback、netty之间混乱关系(史上最全)》pdf
▌实现你的 linux 自由:
- 《linux命令大全:2w多字,一次实现linux自由》pdf
▌实现你的 网络 自由:
- 《tcp协议详解 (史上最全)》pdf
- 《网络三张表:arp表, mac表, 路由表,实现你的网络自由!》pdf
▌实现你的 分布式锁 自由:
- 《redis分布式锁(图解 - 秒懂 - 史上最全)》pdf
- 《zookeeper 分布式锁 - 图解 - 秒懂》pdf
▌实现你的 王者组件 自由:
- 《队列之王: disruptor 原理、架构、源码 一文穿透》pdf
- 《缓存之王:caffeine 源码、架构、原理(史上最全,10w字 超级长文)》pdf
- 《缓存之王:caffeine 的使用(史上最全)》pdf
▌实现你的 面试题 自由:
4000页《尼恩java面试宝典》pdf 40个专题
....
注:以上尼恩 架构笔记、面试题 的pdf文件,请到《技术自由圈》公众号获取
还需要啥自由,可以告诉尼恩 尼恩帮你实现.......
相关文章
-

白色包包好搭配衣服吗(36款白色系大牌包包推荐)
白色包包,小仙女都超爱,尽管白色的很容易弄脏,但真的耐不住它温柔百搭白色本身就是比较圣洁的颜色,,装扮效果也很好搭配不同颜色的服饰就展现出不同的气质,搭浅色系衣服 温暖又清新,搭深色衣服就是全身上下的亮点
2023-09-21 阅读 (94) -

斜跨包包带的钩织方法(钩编方法很简单)
包包钩编2个图案缝合,后面有教程。第一圈图解。钩好后,不与对面连接,直接断线钩第二圈。第二圈效果。第三圈图解。第四圈图解。第五圈图解。后面几圈全部按照第五圈方法钩编。最后一圈顺着边钩编,方法如图 。中间位置两边与中间钩的是长长针。短针缝合。钩一条带子,来回钩一排短针,换线继续钩一排短针。这个是包包中间的图解。
2023-09-16 阅读 (112) -

国际名牌包包前十名爱马仕
前段时间是法棍包诞生25周年,fendi可以说为它风光大办,一口气出了四个联名。虽然这个经典腋下包比我的粉丝们年纪都大,但是在包袋界,属实算是小小辈了。像爱马仕最老的成员hac,出生于1892年,如今还在专柜屹立不倒呢。然后是爱马仕1923年推出的bolide,品牌为了提升自家产品的价值,设计出了史上第一款拉链包。
2023-11-05 阅读 (94) -

第一款包包怎么买便宜一点
大家好,我是大吴哥,但是他不适合高个子女生,也只能搭配衣服用容量很小。总的来说小废包,不实用。locky bb锁头包这款包包虽然容量可以,但是他的锁头很容易有划痕,边角又容易磨损。如果经常用的话,肯定会把包包弄的很受伤啊,所以他也不太适合。蒙田包这个容量很大使用度很高,但是他有点过时了有点老,时代的眼泪罢了。
2023-10-12 阅读 (82) -

YLS包包在法国多少钱(ysl圣罗兰包包价格多少钱)
ysl圣罗兰包包价格多少钱?圣罗兰,来自法国著名的奢侈品牌,在国际上哪是赫赫有名的牌子货哦`特别是它家的包包很有名,既高档又有品味,不过价格也不菲。圣罗兰包包一般多少钱,圣罗兰这种大牌包包价格不用猜肯定不低,那么圣罗兰包包一般多少钱呢?据小编的了解它们家包包的价位贵则的几万,中等价位的一万多,最便宜的也要几千呢。
2023-11-17 阅读 (145) -

范思哲包包怎么样(范思哲包包,是否引领时尚潮流)
什么能治好百病?当然是包包啊~无论什么焦躁、心烦、工作不顺、男友跑路……只要拎上一款品质不错的漂亮手袋,不少姑娘都能笑成花了!今天k先生找来一款品牌强推的手袋,亲自上手体验,看看到底值不值得买。微博:@伪少年k先生在直奔主题之前,先来回答一个问题。提到中文音译为“范思哲”的意大利品牌versace,你会想到什么?
2023-10-01 阅读 (116) -

包包公园是什么档次(包公园)
包公园位于安徽合肥市的环城公园里,始建于北宋年间,是为了纪念北宋著名的清官包拯而建的,而包拯就是合肥人,古往今来他的清正廉洁、铁面无私深受百姓爱戴,在中国具有极高的人格魅力,园内亭台楼阁,花红柳绿,包河穿园而过,水光倒影。来这里游玩既能了解历史又可以散步观景,打卡拍照,是很好的休闲、遛娃、摄影好去处。
2023-10-18 阅读 (131) -

意大利小众包包品牌(有了这几个意大利小众包)
上次和大家分享了8个好看到哭的国内设计师品牌包包,好多妈妈求意大利的小众轻奢包包品牌分享,所以,这次我又来了!今天我要和大家推荐的这些意大利轻奢品牌包包,比上次分享的国内小众包略贵,但是做工、品质,即使和很多奢侈品大牌相比也是没有在怕的!价位大部分和coach、mk差不多(有些甚至还要低哦),但是知道的人并不是很多,所以山寨、烂大街、撞包神马的尴尬问题也都不用担心了。
2023-11-01 阅读 (135) -

包包脏了用什么可以擦干净
都说“包治百病”,特别是一到了夏季,各位小姐姐们恨不得每天都要换一款新包来展示自己的气质吧,但是包包一旦用久了就会有它自己的毛病哦,皮包上难免有各种污渍,瞬间让皮包掉了几个档次!有没有!也会有很多人选择用水擦掉,但是诺淇奢品洗护在这里告诉你,用水擦掉只会越擦越黄!奢侈品皮具护理主要工艺流程:清洁脱膜→加脂复软→补伤打磨→防渗封底→配件保护---调色配色→喷涂上色→颜色固定→增光显色→手感处理→防污防水→配件修饰。
2023-10-31 阅读 (121) -

山茶花包包有几个型号(山茶花包包教程继续)
学习山茶花祖母格包包的钩织方法(四)。曼时光。现在我们来学习如何钩织山茶花。·钩织山茶花的方法。首先使用白色线进行钩织,先从花瓣开始。·起针时,先将线在手上绕两圈,然后用钩针从环中穿出并勾出线。·接着,在钩针上立一个锁针作为起立针。·在环中钩织16个长针,一开始的两个辫子针不算作一个长针,这样就可以直接钩织16个长针了。
2023-10-17 阅读 (108)
热门资讯
-
 2023-10-09 阅读 (3166)
2023-10-09 阅读 (3166) -
 2023-10-28 阅读 (2056)
2023-10-28 阅读 (2056) -
 2023-11-04 阅读 (1258)
2023-11-04 阅读 (1258) -
 2023-11-23 阅读 (929)
2023-11-23 阅读 (929) -
 2023-09-12 阅读 (671)
2023-09-12 阅读 (671)
最新资讯
-
 2023-11-27 阅读 (146)
2023-11-27 阅读 (146) -
 2023-11-27 阅读 (153)
2023-11-27 阅读 (153) -
 2023-11-27 阅读 (154)
2023-11-27 阅读 (154) -
 2023-11-26 阅读 (152)
2023-11-26 阅读 (152) -
 2023-11-26 阅读 (143)
2023-11-26 阅读 (143)